For quite some time, SQLAlchemy has been my go-to database toolkit and ORM for Python microservices and Serverless projects. SQLAlchemy is very powerful and has given me the ability to do pretty much anything I need to do with Postgres, my database of choice nowadays. Of course, the trade off of great power and flexibility is increased complexity. Since SQLAlchemy is a bit more low-level than other ORMs (such as Django, or even Flask’s layer on top of SQLAlchemy) you’re on the hook for dealing with some details that these other ORMs handle automatically.
In this post, I’m going to discuss how to manage database transactions in a serverless environment using SQLAlchemy correctly.
I’m not going to go into great detail about DB transactions themselves. However, I will remind readers that it’s
crucial to close transactions by either executing a DB COMMIT or ROLLBACK statement. If either of these is not
performed after a transaction is started, a database connection will wind up in an idle state and can block other
types of DB operations. I’ll go into more detail below.
Transactions in Web Frameworks
Serverless architectures present new challenges and force us to think about problems differently since the environment is so much different than a typical request/response web context. Traditional web frameworks have a clear and well-defined lifecycle for each request, which could be something like:
pre-requestprocess-requestpost-requestpre-responsesend-responsepost-response
As a concrete example, you can read about Flask’s hooks such as
before_request(),after_request()at this link
Because web frameworks are designed to deal with the web, they can depend on this request/response
cycle and offer hooks to us engineers. As a simple example, when a database is brought into the
picture, we can connect and disconnect in logical places such as pre-request and post-response,
respectively. Any database connection setup would, of course, be started early on in the request
pipeline, and tasks such as closing a connection or putting a connection back into a pool would be
near or at the very end. A post-response hook is a fantastic place to also commit
transactions, or perform a rollback in the case of errors. Either way, it’s a logical place to
tidy up DB transactions and connections so that the DB is left is a “clean” state at the end of an
HTTP request/response cycle.
Serverless architectures do not provide us with these simple hooks. The problem lies in the fact that functions-as-a-service (such as AWS Lambda) are so simple. What I mean here is that web frameworks do quite a bit of work for us and are relatively complicated pieces of software. Lambda functions or other FaaS are much more straightforward and provide next to nothing out of the box. In a genuine sense, they are small functions which execute on our behalf in response to some event. This event may or may not be an HTTP request.
When a Lambda function executes in response to an HTTP event, all of a sudden we’re in a situation where it’d be pretty nice to have some of the typical lifecycle hooks found in modern web frameworks so that we can clean up DB connections and transactions.
The problem is, we don’t have these hooks. HTTP is merely one way to execute our functions. Lambda functions are extremely useful outside of a web request (think data pipelines, triggers from other microservices, triggers from S3 events, etc.)
How do you properly use SQLAlchemy when you don’t have lifecycle hooks to setup and tear-down/close your database connections and commit/rollback transactions?
Consequences of doing it wrong
Before answering that question, let’s look at what happens when you mishandle DB transactions.
It took me quite a while to figure out that I was managing my DB transactions incorrectly in all of my serverless projects. The reason has to do with both the way I structured my code for transaction management in combination with SQLAlchemy’s design. I’m not at all blaming SQLAlchemy…my code was simply assuming a particular behavior that SQLAlchemy doesn’t conform to.
The code and pattern below is something I’ve been using for years, across serverless and non-serverless projects. It’s critical to understand that SQLAlchemy will implicitly start a transaction whenever you starting making ORM queries or statements. As such, you need to commit or rollback these transactions yourself.
I have a mixin class which adds a save() method that will do the work of committing the
transaction.
The definition and usage look like this:
from . import get_session
class ModelMixin:
def save(self, *, commit=True):
session = get_session()
session.add(self)
if commit:
commit_session()
class User(BaseModel, Base):
"""Model for the clients table."""
email = Column(String(128), nullable=False)
name = Column(String(128), nullable=False)Note:
Base, in the example above, is merely thedeclaritive_baseinstance as you can read about here
To use this, I can first create a User and call the save method to get the object/record committed
to the DB. The following would start and commit a transaction just fine.
user = User(email='test@bar.com', name='Brian Zambrano')
user.save()
Now, all is well. However, if you add one more line after the save, a new transaction would be started. Follow the common scenario below of writing something to the DB, then immediately using the ORM object which was written.
# Instantiate a new `User`. DB isn't touched
user = User(email='test@bar.com', name='Brian Zambrano')
# Save will open up a connection via my get_session helper, then commit it with the
# commit_session # helper. Life is good.
user.save()
# With SQLAlchemy, a request for data on a previously created model object will re-query
# the database! This means that a *new* transaction has been started.
print(user.id)The TL;DR here is that if you:
- Write an object to the DB and commit the transaction
- Use the Python ORM object to read data from this object
you have started a second transaction in step 2 and needs to commit it.
My serverless handler functions often did just this. The pseudo-code would be something along the lines of:
def create_thing_handler(event, context):
thing = create_thing_in_db(event.data)
return serialize_to_json(thing)The act of asking for data from thing would start an entirely new transaction, as SQLAlchemy will
go back into the DB to get the data which was written. The end result is that transactions were
left lying around in an idle in transaction state. The subsequent request to my Lambda functions
would work just fine since these connections would start all over again with new BEGIN and COMMIT
statements. Eventually, the connections would be committed, or timeout as the Lambda functions was
expired by AWS.
The same problem exists for my read-only handlers. When reading data, I did not have any transaction management which resulted in the same problem.
def get_thing_handler(event, context):
thing = get_thing_from_db(event.data['id'])
return serialize_to_json(thing)Even if there is a COMMIT statement around get_thing_from_db, the last line will open up a new
transaction which isn’t committed.
The worse problem here is when performing any type of database schema changes. Look at the
table here from Citusdata
which explains what statements will block other statements. In the top row, you will see that
SELECT statements will block ALTER statements.
If you have
SELECTstatements which areidle in transaction,ALTERstatements will be blocked
To demonstrate this, I ran several queries against my REST API from Chapter 2 of my book,
Serverless Design Patterns and Best
Practices. The screenshot
below shows the open connections after hitting a read-only API with a concurrency of 10 using
siege
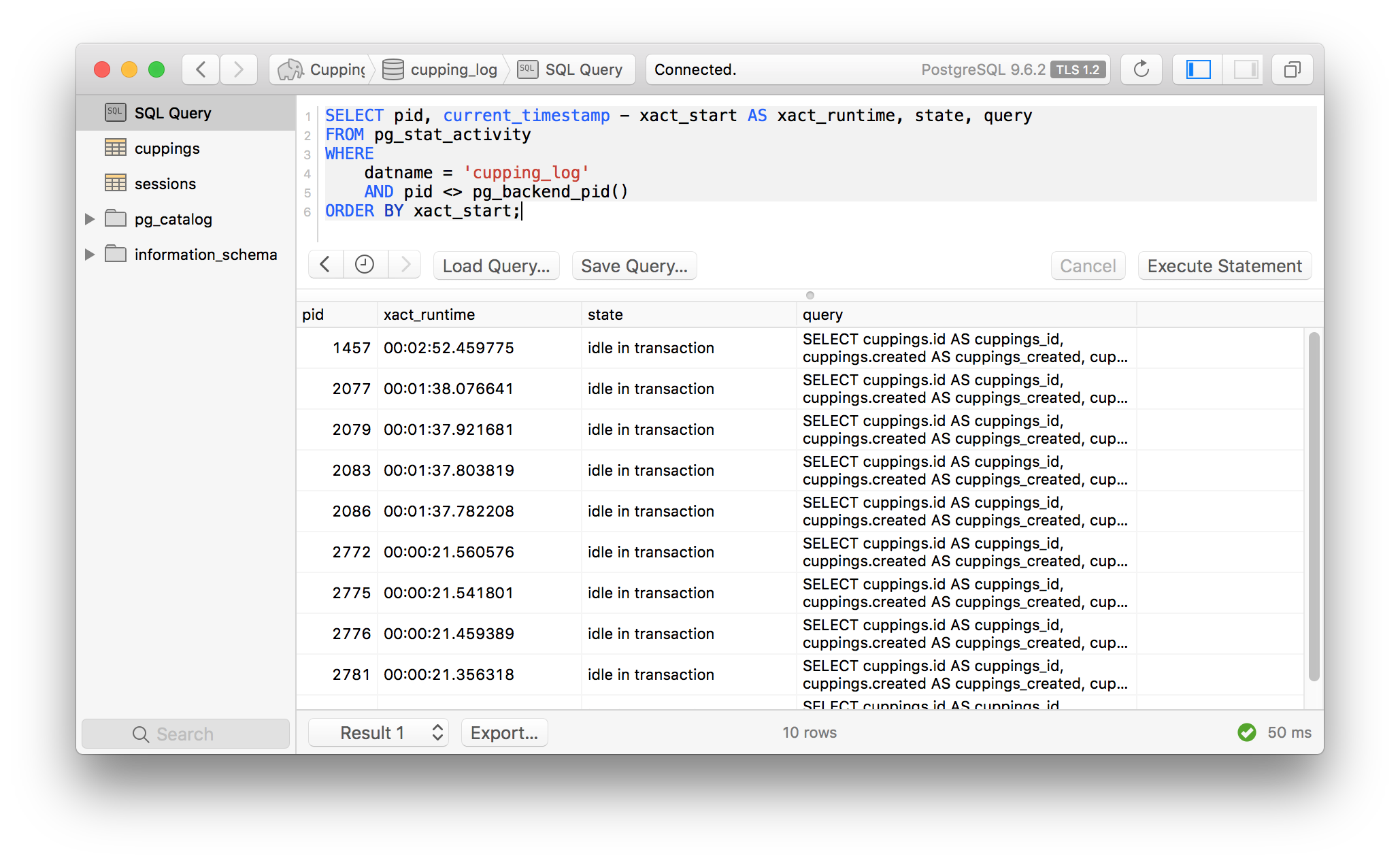
In this state, I issue a simple ALTER table statement which added a column:

This query would just hang. If I queried postgres to determine if the open transactions were
blocking any other transactions, I could very clearly see the reason for my ALTER statement’s
problem:
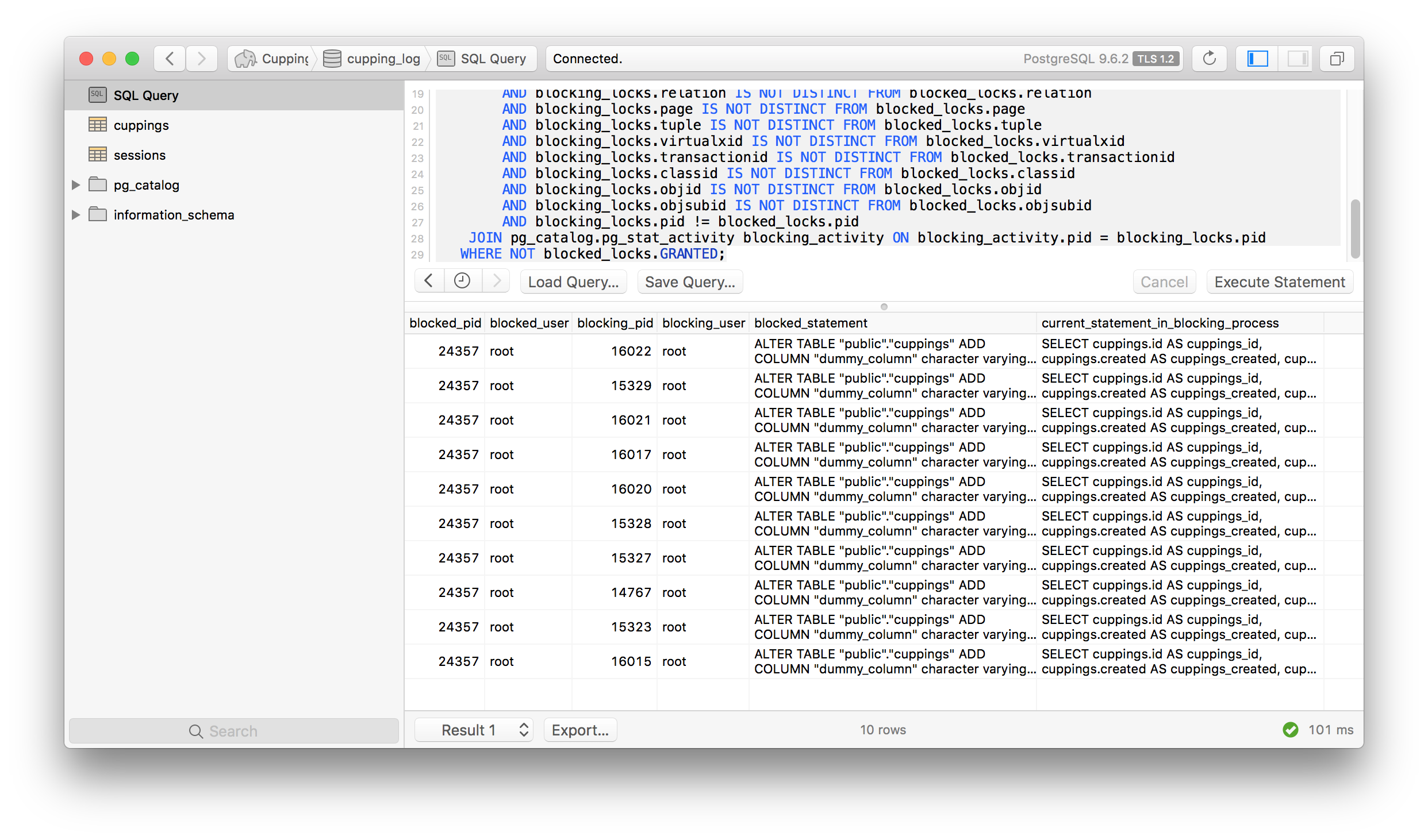
The results above show that my 10 open connections are all idle with SELECT statements, and each
of these is blocking my ALTER table statement.
The fix
The solution which I landed on is a bit coarse but works very well and honestly I can’t think if an
easier or less intrusive way. If we mimic web frameworks, we need to clean up at the end of our handler
function, just before the response is sent back to the client. To accomplish this, I implemented a
decorator which I use around all of my Lambda handler function. My decorator is called
session_committer and looks like this:
def session_committer(func):
"""Decorator to commit the DB session.
Use this from high-level functions such as handler so that the session is always committed or
closed.
"""
def wrapper(*args, **kwargs):
try:
return func(*args, **kwargs)
finally:
commit_session()
return wrapperUsing it is trivial:
@session_committer
def get_thing_handler(event, context):
thing = get_thing_from_db(event.data['id'])
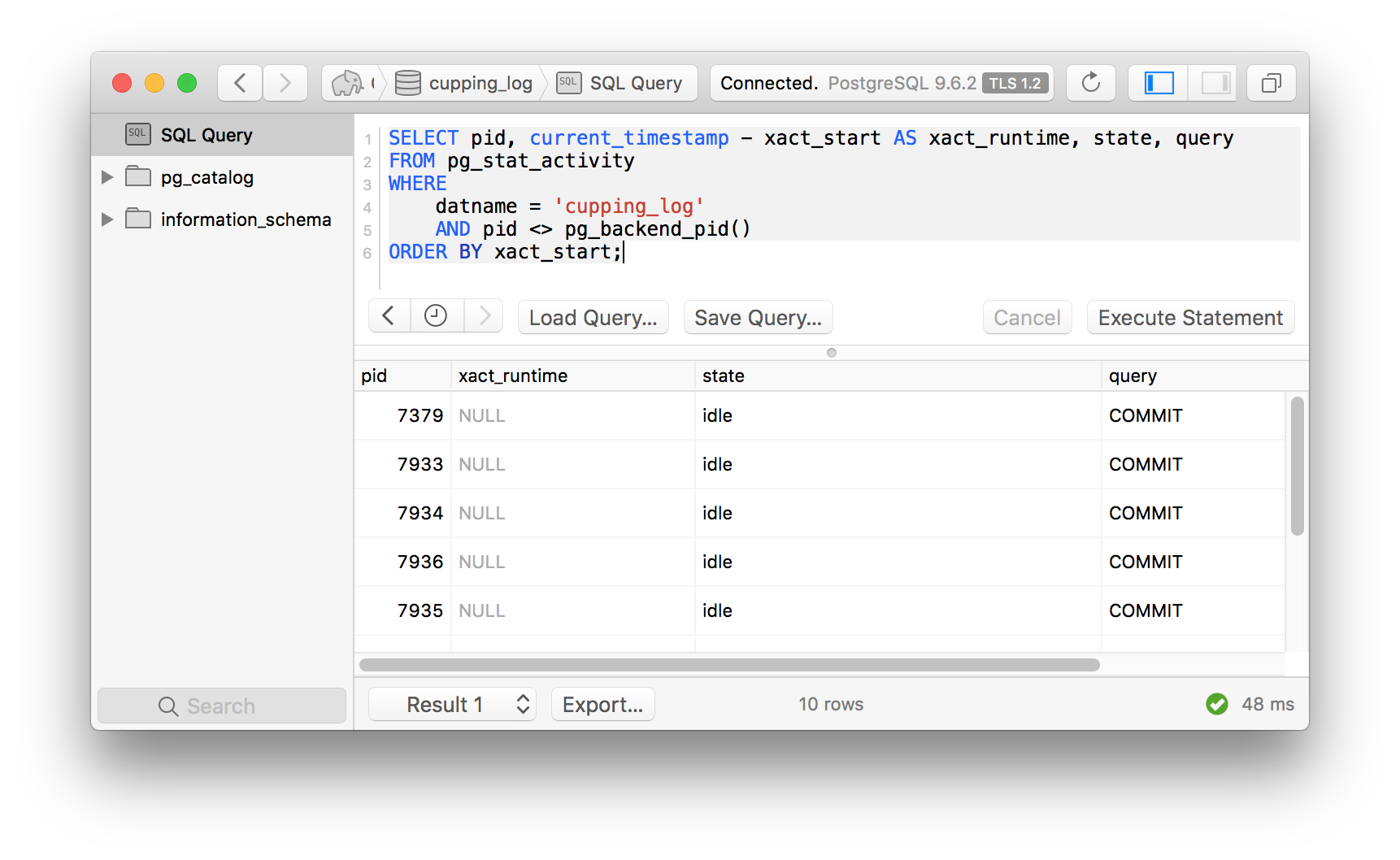
return serialize_to_json(thing)With this change, after running siege I can see that connections have gone from idle in
transaction to simple idle, which means the connection is open but the transaction has be
closed.
Conclusion
Managing database transactions manually is tricky whether you’re using a serverless architecture or not. We often take for granted all of the work which web frameworks provide to us and it can be a rude awakening when we have to deal with housekeeping issues like this ourselves. Still, I believe well-rounded engineers need to understand what is going on with the systems that we use. While SQLAlchemy may be a bit more “raw” than some of the other ORMs out there, it’s extremely powerful and provides you the ability to do nearly anything you need to do.
There is another subject buried in here which has to do with connection pooling in serverless architectures. I plan on covering that in an upcoming post.
If you’d like to take a look at all of my SQLAlchemy helper code, I’ve put it up in the following gist: https://gist.github.com/brianz/feedc052d64212b6576fa42dd6dcadab